Аппроксимация опытных данных. Метод наименьших квадратов. Линейная регрессия. Использование метода наименьших квадратов (МНК) Метод наименьших квадратов предполагает
Если некоторая физическая величина зависит от другой величины, то эту зависимость можно исследовать, измеряя y при различных значениях x . В результате измерений получается ряд значений:
x 1 , x 2 , ..., x i , ... , x n ;
y 1 , y 2 , ..., y i , ... , y n .
По данным такого эксперимента можно построить график зависимости y = ƒ(x). Полученная кривая дает возможность судить о виде функции ƒ(x). Однако постоянные коэффициенты, которые входят в эту функцию, остаются неизвестными. Определить их позволяет метод наименьших квадратов. Экспериментальные точки, как правило, не ложатся точно на кривую. Метод наименьших квадратов требует, чтобы сумма квадратов отклонений экспериментальных точек от кривой, т.е. 2 была наименьшей.
На практике этот метод наиболее часто (и наиболее просто) используется в случае линейной зависимости, т.е. когда
y = kx или y = a + bx.
Линейная зависимость очень широко распространена в физике. И даже когда зависимость нелинейная, обычно стараются строить график так, чтобы получить прямую линию. Например, если предполагают, что показатель преломления стекла n связан с длиной λ световой волны соотношением n = a + b/λ 2 , то на графике строят зависимость n от λ -2 .
Рассмотрим зависимость y = kx (прямая, проходящая через начало координат). Составим величину φ сумму квадратов отклонений наших точек от прямой
Величина φ всегда положительна и оказывается тем меньше, чем ближе к прямой лежат наши точки. Метод наименьших квадратов утверждает, что для k следует выбирать такое значение, при котором φ имеет минимум
![]()
или
(19)
Вычисление показывает, что среднеквадратичная ошибка определения величины k равна при этом
 , (20)
, (20)
где n число измерений.
Рассмотрим теперь несколько более трудный случай, когда точки должны удовлетворить формуле y = a + bx (прямая, не проходящая через начало координат).
Задача состоит в том, чтобы по имеющемуся набору значений x i , y i найти наилучшие значения a и b.
Снова составим квадратичную форму φ , равную сумме квадратов отклонений точек x i , y i от прямой
![]()
и найдем значения a и b , при которых φ имеет минимум
![]() ;
;
![]() .
.
Совместное решение этих уравнений дает
![]() (21)
(21)
Среднеквадратичные ошибки определения a и b равны
 (23)
(23)
 . (24)
. (24)
При обработке результатов измерения этим методом удобно все данные сводить в таблицу, в которой предварительно подсчитываются все суммы, входящие в формулы (19)(24). Формы этих таблиц приведены в рассматриваемых ниже примерах.
Пример 1. Исследовалось основное уравнение динамики вращательного движения ε = M/J (прямая, проходящая через начало координат). При различных значениях момента M измерялось угловое ускорение ε некоторого тела. Требуется определить момент инерции этого тела. Результаты измерений момента силы и углового ускорения занесены во второй и третий столбцы таблицы 5 .
Таблица 5
| n | M, Н · м | ε, c -1 | M 2 | M · ε | ε - kM | (ε - kM) 2 |
| 1 | 1.44 | 0.52 | 2.0736 | 0.7488 | 0.039432 | 0.001555 |
| 2 | 3.12 | 1.06 | 9.7344 | 3.3072 | 0.018768 | 0.000352 |
| 3 | 4.59 | 1.45 | 21.0681 | 6.6555 | -0.08181 | 0.006693 |
| 4 | 5.90 | 1.92 | 34.81 | 11.328 | -0.049 | 0.002401 |
| 5 | 7.45 | 2.56 | 55.5025 | 19.072 | 0.073725 | 0.005435 |
| ∑ | | | 123.1886 | 41.1115 | | 0.016436 |
По формуле (19) определяем:
![]() .
.
Для определения среднеквадратичной ошибки воспользуемся формулой (20)
0.005775 кг -1 · м -2 .
По формуле (18) имеем

S J = (2.996 · 0.005775)/0.3337 = 0.05185 кг · м 2 .
Задавшись надежностью P = 0.95 , по таблице коэффициентов Стьюдента для n = 5, находим t = 2.78 и определяем абсолютную ошибку ΔJ = 2.78 · 0.05185 = 0.1441 ≈ 0.2 кг · м 2 .
Результаты запишем в виде:
J = (3.0 ± 0.2) кг · м 2 ;
Пример 2. Вычислим температурный коэффициент сопротивления металла по методу наименьших квадратов. Сопротивление зависит от температуры по линейному закону
R t = R 0 (1 + α t°) = R 0 + R 0 α t°.
Свободный член определяет сопротивление R 0 при температуре 0° C , а угловой коэффициент произведение температурного коэффициента α на сопротивление R 0 .
Результаты измерений и расчетов приведены в таблице (см. таблицу 6 ).
Таблица 6
| n | t°, c | r, Ом | t-¯ t | (t-¯ t) 2 | (t-¯ t)r | r - bt - a | (r - bt - a) 2 ,10 -6 |
| 1 | 23 | 1.242 | -62.8333 | 3948.028 | -78.039 | 0.007673 | 58.8722 |
| 2 | 59 | 1.326 | -26.8333 | 720.0278 | -35.581 | -0.00353 | 12.4959 |
| 3 | 84 | 1.386 | -1.83333 | 3.361111 | -2.541 | -0.00965 | 93.1506 |
| 4 | 96 | 1.417 | 10.16667 | 103.3611 | 14.40617 | -0.01039 | 107.898 |
| 5 | 120 | 1.512 | 34.16667 | 1167.361 | 51.66 | 0.021141 | 446.932 |
| 6 | 133 | 1.520 | 47.16667 | 2224.694 | 71.69333 | -0.00524 | 27.4556 |
| ∑ | 515 | 8.403 | | 8166.833 | 21.5985 | | 746.804 |
| ∑/n | 85.83333 | 1.4005 | | | | | |
По формулам (21), (22) определяем
R 0 = ¯ R- α R 0 ¯ t = 1.4005 - 0.002645 · 85.83333 = 1.1735 Ом .
Найдем ошибку в определении α. Так как , то по формуле (18) имеем:
 .
.
Пользуясь формулами (23), (24) имеем

 ;
;
0.014126 Ом .
Задавшись надежностью P = 0.95, по таблице коэффициентов Стьюдента для n = 6, находим t = 2.57 и определяем абсолютную ошибку Δα = 2.57 · 0.000132 = 0.000338 град -1 .
α = (23 ± 4) · 10 -4 град
-1 при P = 0.95.
Пример 3. Требуется определить радиус кривизны линзы по кольцам Ньютона. Измерялись радиусы колец Ньютона r m и определялись номера этих колец m. Радиусы колец Ньютона связаны с радиусом кривизны линзы R и номером кольца уравнением
r 2 m = mλR - 2d 0 R,
где d 0 толщина зазора между линзой и плоскопараллельной пластинкой (или деформация линзы),
λ длина волны падающего света.
λ = (600 ± 6) нм;
r 2 m = y;
m = x;
λR = b;
-2d 0 R = a,
тогда уравнение примет вид y = a + bx .
.Результаты измерений и вычислений занесены в таблицу 7 .
Таблица 7
| n | x = m | y = r 2 , 10 -2 мм 2 | m -¯ m | (m -¯ m) 2 | (m -¯ m)y | y - bx - a, 10 -4 | (y - bx - a) 2 , 10 -6 |
| 1 | 1 | 6.101 | -2.5 | 6.25 | -0.152525 | 12.01 | 1.44229 |
| 2 | 2 | 11.834 | -1.5 | 2.25 | -0.17751 | -9.6 | 0.930766 |
| 3 | 3 | 17.808 | -0.5 | 0.25 | -0.08904 | -7.2 | 0.519086 |
| 4 | 4 | 23.814 | 0.5 | 0.25 | 0.11907 | -1.6 | 0.0243955 |
| 5 | 5 | 29.812 | 1.5 | 2.25 | 0.44718 | 3.28 | 0.107646 |
| 6 | 6 | 35.760 | 2.5 | 6.25 | 0.894 | 3.12 | 0.0975819 |
| ∑ | 21 | 125.129 | | 17.5 | 1.041175 | | 3.12176 |
| ∑/n | 3.5 | 20.8548333 | | | | | |
(см. рисунок). Требуется найти уравнение прямой
Чем меньше числа по абсолютной величине, тем лучше подобрана прямая (2). В качестве характеристики точности подбора прямой (2) можно принять сумму квадратов
Условия минимума S будут
 |
(6) |
 |
(7) |
Уравнения (6) и (7) можно записать в таком виде:
 |
(8) |
 |
(9) |
Из уравнений (8) и (9) легко найти a и b по опытным значениям x i и y i . Прямая (2), определяемая уравнениями (8) и (9), называется прямой, полученной по методу наименьших квадратов (этим названием подчеркивается то, что сумма квадратов S имеет минимум). Уравнения (8) и (9), из которых определяется прямая (2), называются нормальными уравнениями.
Можно указать простой и общий способ составления нормальных уравнений. Используя опытные точки (1) и уравнение (2), можно записать систему уравнений для a и b
| y 1 =ax 1 +b, | |||
| y 2 =ax 2 +b, ... |
(10) | ||
| y n =ax n +b, | |||
Умножим левую и правую части каждого из этих уравнений на коэффициент при первой неизвестной a (т.е. на x 1 , x 2 , ..., x n) и сложим полученные уравнения, в результате получится первое нормальное уравнение (8).
Умножим левую и правую части каждого из этих уравнений на коэффициент при второй неизвестной b, т.е. на 1, и сложим полученные уравнения, в результате получится второе нормальное уравнение (9).
Этот способ получения нормальных уравнений является общим: он пригоден, например, и для функции
есть величина постоянная и ее нужно определить по опытным данным (1).
Систему уравнений для k можно записать:
Найти прямую (2) по методу наименьших квадратов.
Решение. Находим:
x i =21, y i =46,3, x i 2 =91, x i y i =179,1.
Записываем уравнения (8) и (9)
Отсюда находим
Оценка точности метода наименьших квадратов
Дадим оценку точности метода для линейного случая, когда имеет место уравнение (2).
Пусть опытные значения x i являются точными, а опытные значения y i имеют случайные ошибки с одинаковой дисперсией для всех i.
Введем обозначение
| (16) |
Тогда решения уравнений (8) и (9) можно представить в виде
| (17) | |
| (18) | |
| где | |
| (19) | |
| Из уравнения (17) находим | |
| (20) | |
| Аналогично из уравнения (18) получаем | |
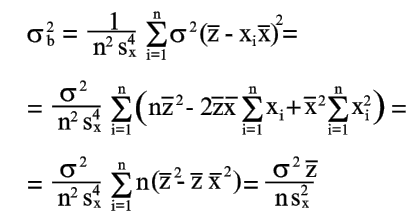 |
(21) |
| так как | |
| (22) | |
| Из уравнений (21) и (22) находим | |
 |
(23) |
Уравнения (20) и (23) дают оценку точности коэффициентов, определенных по уравнениям (8) и (9).
Заметим, что коэффициенты a и b коррелированы. Путем простых преобразований находим их корреляционный момент.
Отсюда находим
0,072 при x=1 и 6,
0,041 при x=3,5.
Литература
Шор. Я. Б. Статистические методы анализа и контроля качества и надежности. М.:Госэнергоиздат, 1962, с. 552, С. 92-98.
Настоящая книга предназначается для широкого круга инженеров (научно-исследовательских институтов, конструкторских бюро, полигонов и заводов), занимающихся определением качества и надежности радиоэлектронной аппаратуры и других массовых изделий промышленности (машиностроения, приборостроения, артиллерийской и т.п.).
В книге дается приложение методов математической статистики к вопросам обработки и оценки результатов испытаний, при которых определяются качество и надежность испытываемых изделий. Для удобства читателей приводятся необходимые сведения из математической статистики, а также большое число вспомогательных математических таблиц, облегчающих проведение необходимых расчетов.
Изложение иллюстрируется большим числом примеров, взятых из области радиоэлектроники и артиллерийской техники.
Метод наименьших квадратов (МНК, англ. Ordinary Least Squares, OLS ) - математический метод, применяемый для решения различных задач, основанный на минимизации суммы квадратов отклонений некоторых функций от искомых переменных. Он может использоваться для «решения» переопределенных систем уравнений (когда количество уравнений превышает количество неизвестных), для поиска решения в случае обычных (не переопределенных) нелинейных систем уравнений, для аппроксимации точечных значений некоторой функции. МНК является одним из базовых методов регрессионного анализа для оценки неизвестных параметров регрессионных моделей по выборочным данным.
Энциклопедичный YouTube
1 / 5
✪ Метод наименьших квадратов. Тема
✪ Метод наименьших квадратов, урок 1/2. Линейная функция
✪ Эконометрика. Лекция 5 .Метод наименьших квадратов
✪ Митин И. В. - Обработка результатов физ. эксперимента - Метод наименьших квадратов (Лекция 4)
✪ Эконометрика: Суть метода наименьших квадратов #2
Субтитры
История
До начала XIX в. учёные не имели определённых правил для решения системы уравнений , в которой число неизвестных меньше, чем число уравнений; до этого времени употреблялись частные приёмы, зависевшие от вида уравнений и от остроумия вычислителей, и потому разные вычислители, исходя из тех же данных наблюдений, приходили к различным выводам. Гауссу (1795) принадлежит первое применение метода, а Лежандр (1805) независимо открыл и опубликовал его под современным названием (фр. Méthode des moindres quarrés ) . Лаплас связал метод с теорией вероятностей , а американский математик Эдрейн (1808) рассмотрел его теоретико-вероятностные приложения . Метод распространён и усовершенствован дальнейшими изысканиями Энке , Бесселя , Ганзена и других.
Сущность метода наименьших квадратов
Пусть x {\displaystyle x} - набор n {\displaystyle n} неизвестных переменных (параметров), f i (x) {\displaystyle f_{i}(x)} , , m > n {\displaystyle m>n} - совокупность функций от этого набора переменных. Задача заключается в подборе таких значений x {\displaystyle x} , чтобы значения этих функций были максимально близки к некоторым значениям y i {\displaystyle y_{i}} . По существу речь идет о «решении» переопределенной системы уравнений f i (x) = y i {\displaystyle f_{i}(x)=y_{i}} , i = 1 , … , m {\displaystyle i=1,\ldots ,m} в указанном смысле максимальной близости левой и правой частей системы. Сущность МНК заключается в выборе в качестве «меры близости» суммы квадратов отклонений левых и правых частей | f i (x) − y i | {\displaystyle |f_{i}(x)-y_{i}|} . Таким образом, сущность МНК может быть выражена следующим образом:
∑ i e i 2 = ∑ i (y i − f i (x)) 2 → min x {\displaystyle \sum _{i}e_{i}^{2}=\sum _{i}(y_{i}-f_{i}(x))^{2}\rightarrow \min _{x}} .В случае, если система уравнений имеет решение, то минимум суммы квадратов будет равен нулю и могут быть найдены точные решения системы уравнений аналитически или, например, различными численными методами оптимизации. Если система переопределена, то есть, говоря нестрого, количество независимых уравнений больше количества искомых переменных, то система не имеет точного решения и метод наименьших квадратов позволяет найти некоторый «оптимальный» вектор x {\displaystyle x} в смысле максимальной близости векторов y {\displaystyle y} и f (x) {\displaystyle f(x)} или максимальной близости вектора отклонений e {\displaystyle e} к нулю (близость понимается в смысле евклидова расстояния).
Пример - система линейных уравнений
В частности, метод наименьших квадратов может использоваться для «решения» системы линейных уравнений
A x = b {\displaystyle Ax=b} ,где A {\displaystyle A} прямоугольная матрица размера m × n , m > n {\displaystyle m\times n,m>n} (т.е. число строк матрицы A больше количества искомых переменных).
Такая система уравнений в общем случае не имеет решения. Поэтому эту систему можно «решить» только в смысле выбора такого вектора x {\displaystyle x} , чтобы минимизировать «расстояние» между векторами A x {\displaystyle Ax} и b {\displaystyle b} . Для этого можно применить критерий минимизации суммы квадратов разностей левой и правой частей уравнений системы, то есть (A x − b) T (A x − b) → min x {\displaystyle (Ax-b)^{T}(Ax-b)\rightarrow \min _{x}} . Нетрудно показать, что решение этой задачи минимизации приводит к решению следующей системы уравнений
A T A x = A T b ⇒ x = (A T A) − 1 A T b {\displaystyle A^{T}Ax=A^{T}b\Rightarrow x=(A^{T}A)^{-1}A^{T}b} .МНК в регрессионном анализе (аппроксимация данных)
Пусть имеется n {\displaystyle n} значений некоторой переменной y {\displaystyle y} (это могут быть результаты наблюдений, экспериментов и т. д.) и соответствующих переменных x {\displaystyle x} . Задача заключается в том, чтобы взаимосвязь между y {\displaystyle y} и x {\displaystyle x} аппроксимировать некоторой функцией , известной с точностью до некоторых неизвестных параметров b {\displaystyle b} , то есть фактически найти наилучшие значения параметров b {\displaystyle b} , максимально приближающие значения f (x , b) {\displaystyle f(x,b)} к фактическим значениям y {\displaystyle y} . Фактически это сводится к случаю «решения» переопределенной системы уравнений относительно b {\displaystyle b} :
F (x t , b) = y t , t = 1 , … , n {\displaystyle f(x_{t},b)=y_{t},t=1,\ldots ,n} .
В регрессионном анализе и в частности в эконометрике используются вероятностные модели зависимости между переменными
Y t = f (x t , b) + ε t {\displaystyle y_{t}=f(x_{t},b)+\varepsilon _{t}} ,
где ε t {\displaystyle \varepsilon _{t}} - так называемые случайные ошибки модели.
Соответственно, отклонения наблюдаемых значений y {\displaystyle y} от модельных f (x , b) {\displaystyle f(x,b)} предполагается уже в самой модели. Сущность МНК (обычного, классического) заключается в том, чтобы найти такие параметры b {\displaystyle b} , при которых сумма квадратов отклонений (ошибок, для регрессионных моделей их часто называют остатками регрессии) e t {\displaystyle e_{t}} будет минимальной:
b ^ O L S = arg min b R S S (b) {\displaystyle {\hat {b}}_{OLS}=\arg \min _{b}RSS(b)} ,где R S S {\displaystyle RSS} - англ. Residual Sum of Squares определяется как:
R S S (b) = e T e = ∑ t = 1 n e t 2 = ∑ t = 1 n (y t − f (x t , b)) 2 {\displaystyle RSS(b)=e^{T}e=\sum _{t=1}^{n}e_{t}^{2}=\sum _{t=1}^{n}(y_{t}-f(x_{t},b))^{2}} .В общем случае решение этой задачи может осуществляться численными методами оптимизации (минимизации). В этом случае говорят о нелинейном МНК (NLS или NLLS - англ. Non-Linear Least Squares ). Во многих случаях можно получить аналитическое решение. Для решения задачи минимизации необходимо найти стационарные точки функции R S S (b) {\displaystyle RSS(b)} , продифференцировав её по неизвестным параметрам b {\displaystyle b} , приравняв производные к нулю и решив полученную систему уравнений:
∑ t = 1 n (y t − f (x t , b)) ∂ f (x t , b) ∂ b = 0 {\displaystyle \sum _{t=1}^{n}(y_{t}-f(x_{t},b)){\frac {\partial f(x_{t},b)}{\partial b}}=0} .МНК в случае линейной регрессии
Пусть регрессионная зависимость является линейной:
y t = ∑ j = 1 k b j x t j + ε = x t T b + ε t {\displaystyle y_{t}=\sum _{j=1}^{k}b_{j}x_{tj}+\varepsilon =x_{t}^{T}b+\varepsilon _{t}} .Пусть y - вектор-столбец наблюдений объясняемой переменной, а X {\displaystyle X} - это (n × k) {\displaystyle ({n\times k})} -матрица наблюдений факторов (строки матрицы - векторы значений факторов в данном наблюдении, по столбцам - вектор значений данного фактора во всех наблюдениях). Матричное представление линейной модели имеет вид:
y = X b + ε {\displaystyle y=Xb+\varepsilon } .Тогда вектор оценок объясняемой переменной и вектор остатков регрессии будут равны
y ^ = X b , e = y − y ^ = y − X b {\displaystyle {\hat {y}}=Xb,\quad e=y-{\hat {y}}=y-Xb} .соответственно сумма квадратов остатков регрессии будет равна
R S S = e T e = (y − X b) T (y − X b) {\displaystyle RSS=e^{T}e=(y-Xb)^{T}(y-Xb)} .Дифференцируя эту функцию по вектору параметров b {\displaystyle b} и приравняв производные к нулю, получим систему уравнений (в матричной форме):
(X T X) b = X T y {\displaystyle (X^{T}X)b=X^{T}y} .В расшифрованной матричной форме эта система уравнений выглядит следующим образом:
(∑ x t 1 2 ∑ x t 1 x t 2 ∑ x t 1 x t 3 … ∑ x t 1 x t k ∑ x t 2 x t 1 ∑ x t 2 2 ∑ x t 2 x t 3 … ∑ x t 2 x t k ∑ x t 3 x t 1 ∑ x t 3 x t 2 ∑ x t 3 2 … ∑ x t 3 x t k ⋮ ⋮ ⋮ ⋱ ⋮ ∑ x t k x t 1 ∑ x t k x t 2 ∑ x t k x t 3 … ∑ x t k 2) (b 1 b 2 b 3 ⋮ b k) = (∑ x t 1 y t ∑ x t 2 y t ∑ x t 3 y t ⋮ ∑ x t k y t) , {\displaystyle {\begin{pmatrix}\sum x_{t1}^{2}&\sum x_{t1}x_{t2}&\sum x_{t1}x_{t3}&\ldots &\sum x_{t1}x_{tk}\\\sum x_{t2}x_{t1}&\sum x_{t2}^{2}&\sum x_{t2}x_{t3}&\ldots &\sum x_{t2}x_{tk}\\\sum x_{t3}x_{t1}&\sum x_{t3}x_{t2}&\sum x_{t3}^{2}&\ldots &\sum x_{t3}x_{tk}\\\vdots &\vdots &\vdots &\ddots &\vdots \\\sum x_{tk}x_{t1}&\sum x_{tk}x_{t2}&\sum x_{tk}x_{t3}&\ldots &\sum x_{tk}^{2}\\\end{pmatrix}}{\begin{pmatrix}b_{1}\\b_{2}\\b_{3}\\\vdots \\b_{k}\\\end{pmatrix}}={\begin{pmatrix}\sum x_{t1}y_{t}\\\sum x_{t2}y_{t}\\\sum x_{t3}y_{t}\\\vdots \\\sum x_{tk}y_{t}\\\end{pmatrix}},} где все суммы берутся по всем допустимым значениям t {\displaystyle t} .
Если в модель включена константа (как обычно), то x t 1 = 1 {\displaystyle x_{t1}=1} при всех t {\displaystyle t} , поэтому в левом верхнем углу матрицы системы уравнений находится количество наблюдений n {\displaystyle n} , а в остальных элементах первой строки и первого столбца - просто суммы значений переменных: ∑ x t j {\displaystyle \sum x_{tj}} и первый элемент правой части системы - ∑ y t {\displaystyle \sum y_{t}} .
Решение этой системы уравнений и дает общую формулу МНК-оценок для линейной модели:
b ^ O L S = (X T X) − 1 X T y = (1 n X T X) − 1 1 n X T y = V x − 1 C x y {\displaystyle {\hat {b}}_{OLS}=(X^{T}X)^{-1}X^{T}y=\left({\frac {1}{n}}X^{T}X\right)^{-1}{\frac {1}{n}}X^{T}y=V_{x}^{-1}C_{xy}} .Для аналитических целей оказывается полезным последнее представление этой формулы (в системе уравнений при делении на n, вместо сумм фигурируют средние арифметические). Если в регрессионной модели данные центрированы , то в этом представлении первая матрица имеет смысл выборочной ковариационной матрицы факторов, а вторая - вектор ковариаций факторов с зависимой переменной. Если кроме того данные ещё и нормированы на СКО (то есть в конечном итоге стандартизированы ), то первая матрица имеет смысл выборочной корреляционной матрицы факторов, второй вектор - вектора выборочных корреляций факторов с зависимой переменной.
Немаловажное свойство МНК-оценок для моделей с константой - линия построенной регрессии проходит через центр тяжести выборочных данных, то есть выполняется равенство:
y ¯ = b 1 ^ + ∑ j = 2 k b ^ j x ¯ j {\displaystyle {\bar {y}}={\hat {b_{1}}}+\sum _{j=2}^{k}{\hat {b}}_{j}{\bar {x}}_{j}} .В частности, в крайнем случае, когда единственным регрессором является константа, получаем, что МНК-оценка единственного параметра (собственно константы) равна среднему значению объясняемой переменной. То есть среднее арифметическое, известное своими хорошими свойствами из законов больших чисел, также является МНК-оценкой - удовлетворяет критерию минимума суммы квадратов отклонений от неё.
Простейшие частные случаи
В случае парной линейной регрессии y t = a + b x t + ε t {\displaystyle y_{t}=a+bx_{t}+\varepsilon _{t}} , когда оценивается линейная зависимость одной переменной от другой, формулы расчета упрощаются (можно обойтись без матричной алгебры). Система уравнений имеет вид:
(1 x ¯ x ¯ x 2 ¯) (a b) = (y ¯ x y ¯) {\displaystyle {\begin{pmatrix}1&{\bar {x}}\\{\bar {x}}&{\bar {x^{2}}}\\\end{pmatrix}}{\begin{pmatrix}a\\b\\\end{pmatrix}}={\begin{pmatrix}{\bar {y}}\\{\overline {xy}}\\\end{pmatrix}}} .Отсюда несложно найти оценки коэффициентов:
{ b ^ = Cov (x , y) Var (x) = x y ¯ − x ¯ y ¯ x 2 ¯ − x ¯ 2 , a ^ = y ¯ − b x ¯ . {\displaystyle {\begin{cases}{\hat {b}}={\frac {\mathop {\textrm {Cov}} (x,y)}{\mathop {\textrm {Var}} (x)}}={\frac {{\overline {xy}}-{\bar {x}}{\bar {y}}}{{\overline {x^{2}}}-{\overline {x}}^{2}}},\\{\hat {a}}={\bar {y}}-b{\bar {x}}.\end{cases}}}Несмотря на то что в общем случае модели с константой предпочтительней, в некоторых случаях из теоретических соображений известно, что константа a {\displaystyle a} должна быть равна нулю. Например, в физике зависимость между напряжением и силой тока имеет вид U = I ⋅ R {\displaystyle U=I\cdot R} ; замеряя напряжение и силу тока, необходимо оценить сопротивление. В таком случае речь идёт о модели y = b x {\displaystyle y=bx} . В этом случае вместо системы уравнений имеем единственное уравнение
(∑ x t 2) b = ∑ x t y t {\displaystyle \left(\sum x_{t}^{2}\right)b=\sum x_{t}y_{t}} .
Следовательно, формула оценки единственного коэффициента имеет вид
B ^ = ∑ t = 1 n x t y t ∑ t = 1 n x t 2 = x y ¯ x 2 ¯ {\displaystyle {\hat {b}}={\frac {\sum _{t=1}^{n}x_{t}y_{t}}{\sum _{t=1}^{n}x_{t}^{2}}}={\frac {\overline {xy}}{\overline {x^{2}}}}} .
Случай полиномиальной модели
Если данные аппроксимируются полиномиальной функцией регрессии одной переменной f (x) = b 0 + ∑ i = 1 k b i x i {\displaystyle f(x)=b_{0}+\sum \limits _{i=1}^{k}b_{i}x^{i}} , то, воспринимая степени x i {\displaystyle x^{i}} как независимые факторы для каждого i {\displaystyle i} можно оценить параметры модели исходя из общей формулы оценки параметров линейной модели. Для этого в общую формулу достаточно учесть, что при такой интерпретации x t i x t j = x t i x t j = x t i + j {\displaystyle x_{ti}x_{tj}=x_{t}^{i}x_{t}^{j}=x_{t}^{i+j}} и x t j y t = x t j y t {\displaystyle x_{tj}y_{t}=x_{t}^{j}y_{t}} . Следовательно, матричные уравнения в данном случае примут вид:
(n ∑ n x t … ∑ n x t k ∑ n x t ∑ n x t 2 … ∑ n x t k + 1 ⋮ ⋮ ⋱ ⋮ ∑ n x t k ∑ n x t k + 1 … ∑ n x t 2 k) [ b 0 b 1 ⋮ b k ] = [ ∑ n y t ∑ n x t y t ⋮ ∑ n x t k y t ] . {\displaystyle {\begin{pmatrix}n&\sum \limits _{n}x_{t}&\ldots &\sum \limits _{n}x_{t}^{k}\\\sum \limits _{n}x_{t}&\sum \limits _{n}x_{t}^{2}&\ldots &\sum \limits _{n}x_{t}^{k+1}\\\vdots &\vdots &\ddots &\vdots \\\sum \limits _{n}x_{t}^{k}&\sum \limits _{n}x_{t}^{k+1}&\ldots &\sum \limits _{n}x_{t}^{2k}\end{pmatrix}}{\begin{bmatrix}b_{0}\\b_{1}\\\vdots \\b_{k}\end{bmatrix}}={\begin{bmatrix}\sum \limits _{n}y_{t}\\\sum \limits _{n}x_{t}y_{t}\\\vdots \\\sum \limits _{n}x_{t}^{k}y_{t}\end{bmatrix}}.}
Статистические свойства МНК-оценок
В первую очередь, отметим, что для линейных моделей МНК-оценки являются линейными оценками, как это следует из вышеприведённой формулы. Для несмещенности МНК-оценок необходимо и достаточно выполнения важнейшего условия регрессионного анализа : условное по факторам математическое ожидание случайной ошибки должно быть равно нулю. Данное условие, в частности, выполнено, если
- математическое ожидание случайных ошибок равно нулю, и
- факторы и случайные ошибки - независимые случайные величины .
Второе условие - условие экзогенности факторов - принципиальное. Если это свойство не выполнено, то можно считать, что практически любые оценки будут крайне неудовлетворительными: они не будут даже состоятельными (то есть даже очень большой объём данных не позволяет получить качественные оценки в этом случае). В классическом случае делается более сильное предположение о детерминированности факторов, в отличие от случайной ошибки, что автоматически означает выполнение условия экзогенности. В общем случае для состоятельности оценок достаточно выполнения условия экзогенности вместе со сходимостью матрицы V x {\displaystyle V_{x}} к некоторой невырожденной матрице при увеличении объёма выборки до бесконечности.
Для того, чтобы кроме состоятельности и несмещенности , оценки (обычного) МНК были ещё и эффективными (наилучшими в классе линейных несмещенных оценок) необходимо выполнение дополнительных свойств случайной ошибки:
Данные предположения можно сформулировать для ковариационной матрицы вектора случайных ошибок V (ε) = σ 2 I {\displaystyle V(\varepsilon)=\sigma ^{2}I} .
Линейная модель, удовлетворяющая таким условиям, называется классической . МНК-оценки для классической линейной регрессии являются несмещёнными , состоятельными и наиболее эффективными оценками в классе всех линейных несмещённых оценок (в англоязычной литературе иногда употребляют аббревиатуру BLUE (Best Linear Unbiased Estimator ) - наилучшая линейная несмещённая оценка; в отечественной литературе чаще приводится теорема Гаусса - Маркова). Как нетрудно показать, ковариационная матрица вектора оценок коэффициентов будет равна:
V (b ^ O L S) = σ 2 (X T X) − 1 {\displaystyle V({\hat {b}}_{OLS})=\sigma ^{2}(X^{T}X)^{-1}} .
Эффективность означает, что эта ковариационная матрица является «минимальной» (любая линейная комбинация коэффициентов, и в частности сами коэффициенты, имеют минимальную дисперсию), то есть в классе линейных несмещенных оценок оценки МНК-наилучшие. Диагональные элементы этой матрицы - дисперсии оценок коэффициентов - важные параметры качества полученных оценок. Однако рассчитать ковариационную матрицу невозможно, поскольку дисперсия случайных ошибок неизвестна. Можно доказать, что несмещённой и состоятельной (для классической линейной модели) оценкой дисперсии случайных ошибок является величина:
S 2 = R S S / (n − k) {\displaystyle s^{2}=RSS/(n-k)} .
Подставив данное значение в формулу для ковариационной матрицы и получим оценку ковариационной матрицы. Полученные оценки также являются несмещёнными и состоятельными . Важно также то, что оценка дисперсии ошибок (а значит и дисперсий коэффициентов) и оценки параметров модели являются независимыми случайными величинами, что позволяет получить тестовые статистики для проверки гипотез о коэффициентах модели.
Необходимо отметить, что если классические предположения не выполнены, МНК-оценки параметров не являются наиболее эффективными и, где W {\displaystyle W} - некоторая симметрическая положительно определенная весовая матрица. Обычный МНК является частным случаем данного подхода, когда весовая матрица пропорциональна единичной матрице. Как известно, для симметрических матриц (или операторов) существует разложение W = P T P {\displaystyle W=P^{T}P} . Следовательно, указанный функционал можно представить следующим образом e T P T P e = (P e) T P e = e ∗ T e ∗ {\displaystyle e^{T}P^{T}Pe=(Pe)^{T}Pe=e_{*}^{T}e_{*}} , то есть этот функционал можно представить как сумму квадратов некоторых преобразованных «остатков». Таким образом, можно выделить класс методов наименьших квадратов - LS-методы (Least Squares).
Доказано (теорема Айткена), что для обобщенной линейной регрессионной модели (в которой на ковариационную матрицу случайных ошибок не налагается никаких ограничений) наиболее эффективными (в классе линейных несмещенных оценок) являются оценки т. н. обобщенного МНК (ОМНК, GLS - Generalized Least Squares) - LS-метода с весовой матрицей, равной обратной ковариационной матрице случайных ошибок: W = V ε − 1 {\displaystyle W=V_{\varepsilon }^{-1}} .
Можно показать, что формула ОМНК-оценок параметров линейной модели имеет вид
B ^ G L S = (X T V − 1 X) − 1 X T V − 1 y {\displaystyle {\hat {b}}_{GLS}=(X^{T}V^{-1}X)^{-1}X^{T}V^{-1}y} .
Ковариационная матрица этих оценок соответственно будет равна
V (b ^ G L S) = (X T V − 1 X) − 1 {\displaystyle V({\hat {b}}_{GLS})=(X^{T}V^{-1}X)^{-1}} .
Фактически сущность ОМНК заключается в определенном (линейном) преобразовании (P) исходных данных и применении обычного МНК к преобразованным данным. Цель этого преобразования - для преобразованных данных случайные ошибки уже удовлетворяют классическим предположениям.
Взвешенный МНК
В случае диагональной весовой матрицы (а значит и ковариационной матрицы случайных ошибок) имеем так называемый взвешенный МНК (WLS - Weighted Least Squares). В данном случае минимизируется взвешенная сумма квадратов остатков модели, то есть каждое наблюдение получает «вес», обратно пропорциональный дисперсии случайной ошибки в данном наблюдении: e T W e = ∑ t = 1 n e t 2 σ t 2 {\displaystyle e^{T}We=\sum _{t=1}^{n}{\frac {e_{t}^{2}}{\sigma _{t}^{2}}}} . Фактически данные преобразуются взвешиванием наблюдений (делением на величину, пропорциональную предполагаемому стандартному отклонению случайных ошибок), а к взвешенным данным применяется обычный МНК.
ISBN 978-5-7749-0473-0 .
3. Аппроксимация функций с помощью метода
наименьших квадратов
Метод наименьших квадратов применяется при обработке результатов эксперимента для аппроксимации (приближения) экспериментальных данных аналитической формулой. Конкретный вид формулы выбирается, как правило, из физических соображений. Такими формулами могут быть:
![]()
![]()
и другие.
Сущность метода наименьших квадратов состоит в следующем. Пусть результаты измерений представлены таблицей:
|
Таблица 4 |
||||
|
x n |
||||
|
y n |
||||
|
(3.1) |
где f - известная функция, a 0 , a 1 , …, a m - неизвестные постоянные параметры, значения которых надо найти. В методе наименьших квадратов приближение функции (3.1) к экспериментальной зависимости считается наилучшим, если выполняется условие
|
(3.2) |
то есть сумм a квадратов отклонений искомой аналитической функции от экспериментальной зависимости должна быть минимальна .
Заметим, что функция Q называется невязкой.

Так как невязка

то она имеет минимум. Необходимым условием минимума функции нескольких переменных является равенство нулю всех частных производных этой функции по параметрам. Таким образом, отыскание наилучших значений параметров аппроксимирующей функции (3.1), то есть таких их значений, при которых Q = Q (a 0 , a 1 , …, a m ) минимальна, сводится к решению системы уравнений:
|
(3.3) |
Методу наименьших квадратов можно дать следующее геометрическое истолкование: среди бесконечного семейства линий данного вида отыскивается одна линия, для которой сумма квадратов разностей ординат экспериментальных точек и соответствующих им ординат точек, найденных по уравнению этой линии, будет наименьшей.
Нахождение параметров линейной функции
Пусть экспериментальные данные надо представить линейной функцией:
Требуется подобрать такие значения a и b , для которых функция
|
(3.4) |
будет минимальной. Необходимые условия минимума функции (3.4) сводятся к системе уравнений:
|
|

После преобразований получаем систему двух линейных уравнений с двумя неизвестными:
|
|
(3.5) |

решая которую , находим искомые значения параметров a и b .
Нахождение параметров квадратичной функции
Если аппроксимирующей функцией является квадратичная зависимость
то её параметры a , b , c находят из условия минимума функции:
|
(3.6) |
Условия минимума функции (3.6) сводятся к системе уравнений:
|
|

После преобразований получаем систему трёх линейных уравнений с тремя неизвестными:
|
|
(3.7) |

при решении которой находим искомые значения параметров a , b и c .
Пример . Пусть в результате эксперимента получена следующая таблица значений x и y :
|
Таблица 5 |
||||||||
|
y i |
0,705 |
0,495 |
0,426 |
0,357 |
0,368 |
0,406 |
0,549 |
0,768 |
Требуется аппроксимировать экспериментальные данные линейной и квадратичной функциями.
Решение. Отыскание параметров аппроксимирующих функций сводится к решению систем линейных уравнений (3.5) и (3.7). Для решения задачи воспользуемся процессором электронных таблиц Excel .
1. Сначала сцепим листы 1 и 2. Занесём экспериментальные значения x i и y i в столбцы А и В, начиная со второй строки (в первой строке поместим заголовки столбцов). Затем для этих столбцов вычислим суммы и поместим их в десятой строке.
В столбцах C – G разместим соответственно вычисление и суммирование
2. Расцепим листы.Дальнейшие вычисления проведём аналогичным образом для линейной зависимости на Листе 1и для квадратичной зависимости на Листе 2.
3. Под полученной таблицей сформируем матрицу коэффициентов и вектор-столбец свободных членов. Решим систему линейных уравнений по следующему алгоритму:
Для вычисления обратной матрицы и перемножения матриц воспользуемся Мастером функций и функциями МОБР и МУМНОЖ .
4. В блоке ячеек H2: H 9 на основе полученных коэффициентов вычислим значенияаппроксимирующего полинома y i выч ., в блоке I 2: I 9 – отклонения D y i = y i эксп . - y i выч .,в столбце J – невязку:
Полученные таблицы и построенные с помощью Мастера диаграмм графики приведёны на рисунках6, 7, 8.

Рис. 6. Таблица вычисления коэффициентов линейной функции,
аппроксимирующей экспериментальные данные.

Рис. 7. Таблица вычисления коэффициентов квадратичной функции,
аппроксимирующей экспериментальные данные.

Рис. 8. Графическое представление результатов аппроксимации
экспериментальных данных линейной и квадратичной функциями.
Ответ. Аппроксимировали экспериментальные данные линейной зависимостью y = 0,07881 x + 0,442262 c невязкой Q = 0,165167 и квадратичной зависимостью y = 3,115476 x 2 – 5,2175 x + 2,529631 c невязкой Q = 0,002103 .
Задания. Аппроксимировать функцию, заданную таблично, линейной и квадратичной функциями.
|
Таблица 6 |
|||||||||
|
№0 |
x |
0,1 |
0,2 |
0,3 |
0,4 |
0,5 |
0,6 |
0,7 |
0,8 |
|
y |
3,030 |
3,142 |
3,358 |
3,463 |
3,772 |
3,251 |
3,170 |
3,665 |
|
|
№ 1 |
|||||||||
|
3,314 |
3,278 |
3,262 |
3,292 |
3,332 |
3,397 |
3,487 |
3,563 |
||
|
№ 2 |
|||||||||
|
1,045 |
1,162 |
1,264 |
1,172 |
1,070 |
0,898 |
0,656 |
0,344 |
||
|
№ 3 |
|||||||||
|
6,715 |
6,735 |
6,750 |
6,741 |
6,645 |
6,639 |
6,647 |
6,612 |
||
|
№ 4 |
|||||||||
|
2,325 |
2,515 |
2,638 |
2,700 |
2,696 |
2,626 |
2,491 |
2,291 |
||
|
№ 5 |
|||||||||
|
1.752 |
1,762 |
1,777 |
1,797 |
1,821 |
1,850 |
1,884 |
1,944 |
||
|
№ 6 |
|||||||||
|
1,924 |
1,710 |
1,525 |
1,370 |
1,264 |
1,190 |
1,148 |
1,127 |
||
|
№ 7 |
|||||||||
|
1,025 |
1,144 |
1,336 |
1,419 |
1,479 |
1,530 |
1,568 |
1,248 |
||
|
№ 8 |
|||||||||
|
5,785 |
5,685 |
5,605 |
5,545 |
5,505 |
5,480 |
5,495 |
5,510 |
||
|
№ 9 |
|||||||||
|
4,052 |
4,092 |
4,152 |
4,234 |
4,338 |
4,468 |
4,599 |
Метод наименьших квадратов
используется для оценки параметров уравнение регрессии.
Одним из методов изучения стохастических связей между признаками является регрессионный анализ .
В случае линейной парной связи уравнение регрессии примет вид: y i =a+b·x i +u i . Параметры данного уравнения а и b оцениваются по данным статистического наблюдения x и y . Результатом такой оценки является уравнение: , где , - оценки параметров a и b , - значение результативного признака (переменной), полученное по уравнению регрессии (расчетное значение). Наиболее часто для оценки параметров используют метод наименьших квадратов (МНК).
Задача оценивания параметров линейного парного уравнения методом наименьших квадратов
состоит в следующем: получить такие оценки параметров , , при которых сумма квадратов отклонений фактических значений результативного признака - y i от расчетных значений – минимальна.
Классификация методов наименьших квадратов
Проиллюстрируем суть классического метода наименьших квадратов графически
. Для этого построим точечный график по данным наблюдений (x i , y i , i=1;n) в прямоугольной системе координат (такой точечный график называют корреляционным полем). Попытаемся подобрать прямую линию, которая ближе всего расположена к точкам корреляционного поля. Согласно методу наименьших квадратов линия выбирается так, чтобы сумма квадратов расстояний по вертикали между точками корреляционного поля и этой линией была бы минимальной.
Оценка тесноты связи между признаками
осуществляется с помощью коэффициента линейной парной корреляции - r x,y .
Он может быть рассчитан по формуле: Для оценки качества полученного уравнения регрессии рассчитывают теоретический коэффициент детерминации – R 2 yx:
Не нашли ответ на свой вопрос? Посмотрите здесь
| ||
 .
.
 .
.
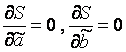 .
.


 . Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b:
. Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b:  .
.
 ,
,
 Как приготовить утку с картошкой в духовке
Как приготовить утку с картошкой в духовке Малина, черника и другие ягоды протёртые с сахаром
Малина, черника и другие ягоды протёртые с сахаром Торт с рыбой. Закусочный рыбный торт. Кбжу и состав для всего блюда
Торт с рыбой. Закусочный рыбный торт. Кбжу и состав для всего блюда